I'm thrilled to announce the new and shiny addition to the Karafka ecosystem: Karafka Web.
For those who wonder what Karafka is, Karafka is a Ruby and Rails multi-threaded efficient Kafka processing framework.
Karafka has always been a convenient framework, and I've abstracted or hidden many complexities related to working with Apache Kafka. However, the ecosystem needed one essential thing: a Web UI.
Until now, you would have to rely on external tooling to get visibility into your Karafka operations. While this is not problematic for big businesses, solid observability is difficult for anyone just starting their adventure with Karafka and Kafka.
Today I have the pleasure of presenting an effect of the last six months of my OSS work: Karafka Web. The Web UI provides a convenient way for developers to monitor and manage their Karafka-based applications without using the command line or third-party software. It does not require any additional database beyond Kafka itself.
"Hey, this looks like Sidekiq" you may say. And this is true! Mike was kind enough to allow me to utilize his well-curated and battle-tested dashboard design; honestly, I cannot thank him enough for that.
Features and capabilities
I've been working with Apache Kafka for over eight years, and I always wished we had a tool that could be easily mounted and used as a Rack application that would provide process-centric visibility. There are many excellent Web UIs for Apache Kafka, though most of them focus on Kafka. Karafka Web aims to provide another layer of visibility that is Karafka consumers-centric, allowing you to understand and debug your consumption operations.
# Mounting is simple as it can be
require 'karafka/web'
Rails.application.routes.draw do
# Your other routes...
mount Karafka::Web::App, at: '/karafka'
end
Below you can find the presentation of features I consider the most notable.
Note: You can find the whole list of features and capabilities described here.
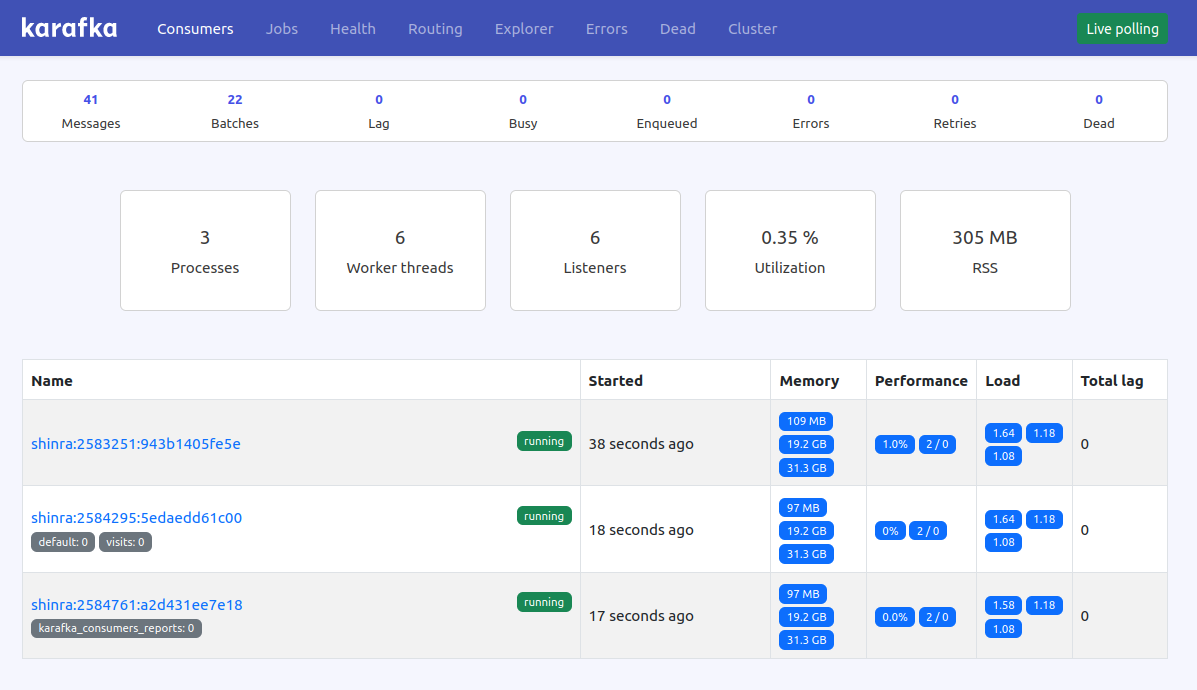
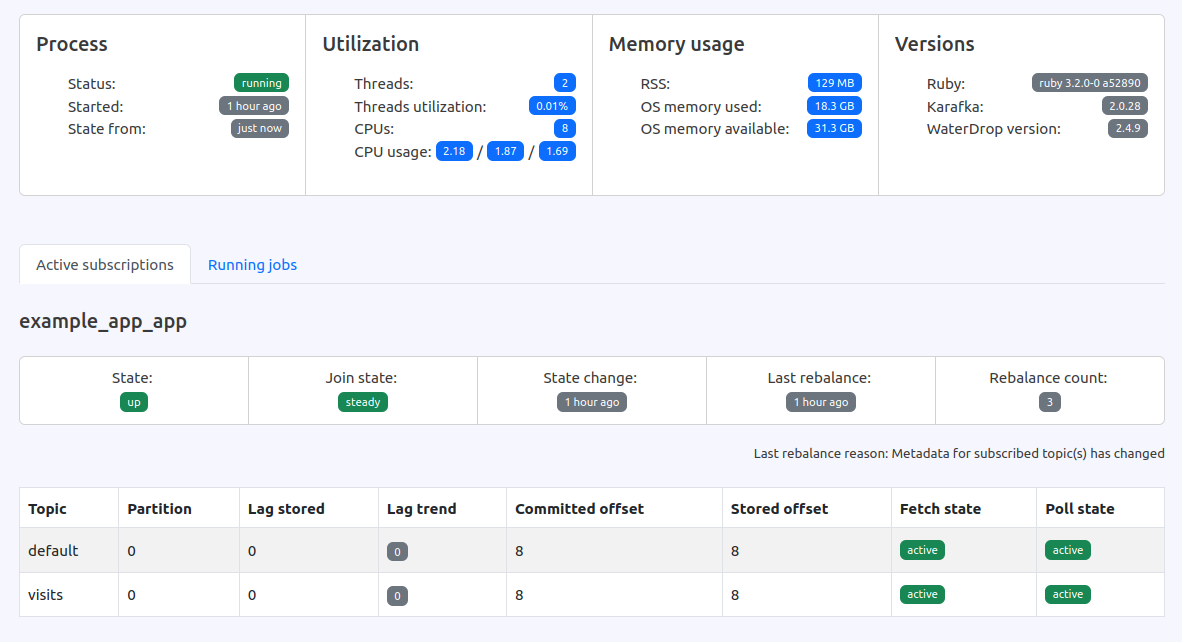
Consumers monitoring and insights
Each Karafka consumer periodically reports its status and metrics to a dedicated Kafka topic. This data is then used to compute aggregated metrics and provide visibility into the current operations of each consuming process.
Consumers monitoring gives you a general overview and granular insights into each of the running processes. Ever wondered whether your processes are IO or CPU bound at a given time? Or how loaded are your processes? Now you can check it out with one click!
Data Explorer
Data explorer allows users to view and explore the data produced to Kafka. It understands the Karafka routing table and can deserialize data before it being displayed. It allows for quick investigation of both payload and header information.
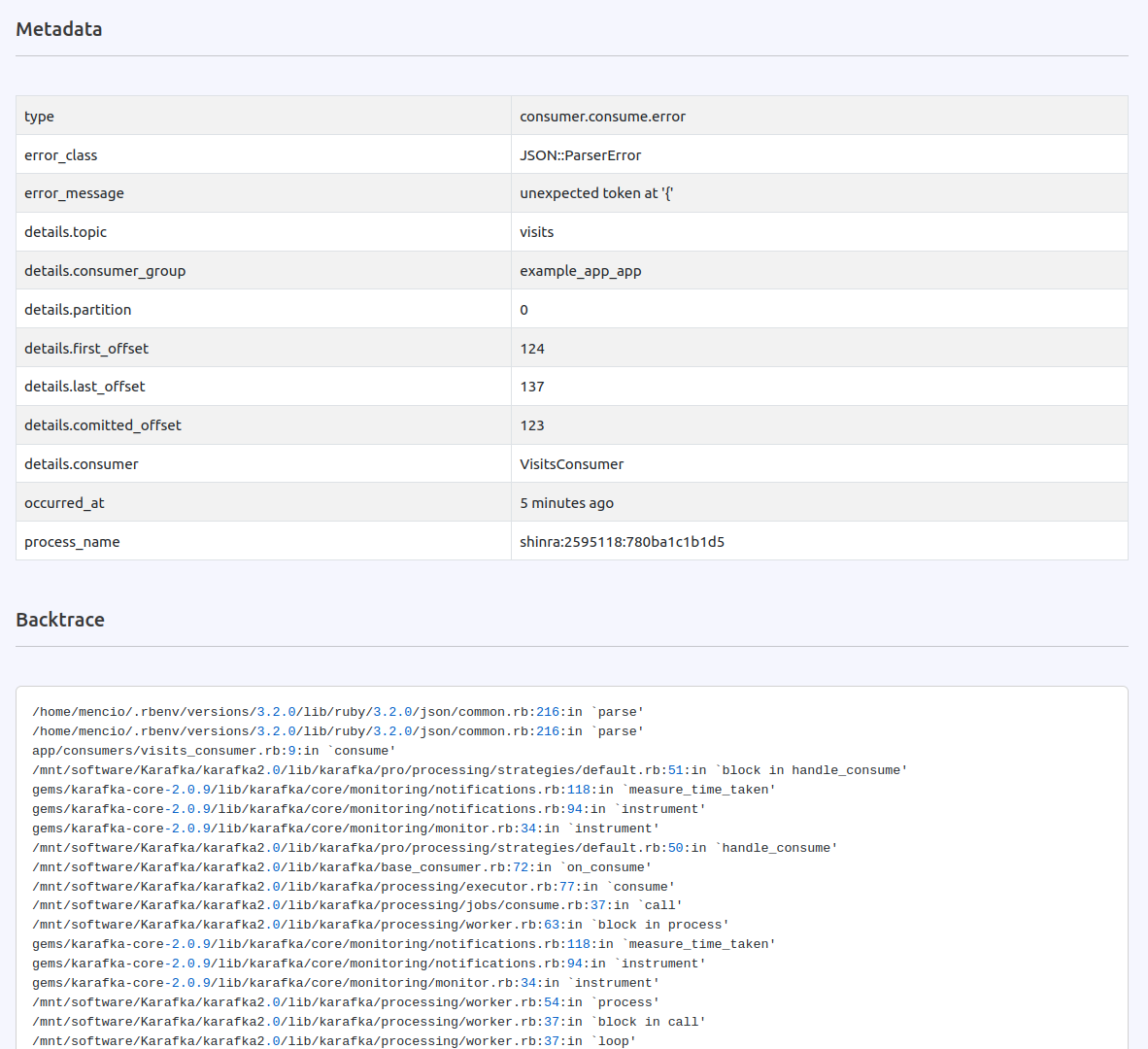
Error tracking
Karafka consumers are multi-threaded. The consumption process happens independently from data polling. There is a lot of synchronization, and not all the errors propagate to the consumer threads. Karafka records all the errors, including the non-user-related ones, and presents them in the errors view.
The example Rails repository already contains the Web UI and detailed instructions on how to run it.
Support
Building and maintaining a complex OSS framework takes a lot of resources. That's why I also sell Karafka Pro subscriptions. It includes a commercial-friendly license, priority support, architecture consultations, enhanced Web UI and high throughput data processing-related features (virtual partitions, long-running jobs, and more).
Help me provide high-quality open-source software. If your business rely on Karafka, please consider supporting me. See the Karafka homepage for more details.
Future plans
My primary Web UI-related efforts revolve around providing trend graphs for better health assessment and visibility to diagnose potential lagging and clogging issues quickly.
TL;DR
No UI: bad.
Out-of-the-box OSS Karafka Web UI: great.
No third party dependencies, minimal supply chain fingerprint, works out-of-the-box.
For the past several weeks, I've been trying to fix a cranky spec in Karafka integrations suite, which in the end, lead me to become a Ruby on Rails micro-contributor and submitting similar fix to several other high-popularity projects from the Ruby ecosystem. Here's my story of trying to make sense of my specs and Ruby concurrency.
Ephemeral bug from a test-suite
Karafka is a Ruby and Rails multi-threaded efficient Kafka processing framework. To provide reliable OSS that is multi-threaded, I had to have the option to run my test suite concurrently to simulate how Karafka operates. Since it was a specific use case, I created my micro-framework.
Long story short: It runs end-to-end integration specs by running them in separate Ruby processes. Each starts Karafka, runs all the code in various configurations, connects to Kafka, checks assertions, and at the end, shuts down.
Such an approach allowed me to ensure that the process's whole lifecycle and its components work as expected. Specs are started with supervision, so in case of any hang, it will be killed after 5 minutes.
Karafka itself also has an internal shutdown supervisor. In case of a user shutdown request, if the shutdown takes longer than the defined expected time, Karafka will stop despite having things running. And this is what was happening with this single spec:
workers that process jobs that could hang and force the process to wait
jobs queue that is also connected to the polling thread (to poll more data when no work is to be done)
listeners that poll data from Kafka that could hang
consumer groups with several threads polling Kafka data that might get stuck because of some underlying error
Other bugs in the coordination of work and states.
One thing that certainly worked was the process supervision that would forcefully kill it after 30 seconds.
Process shutdown coordination
The graceful shutdown of such a process takes work. When you have many connections to Kafka, upon a poorly organized shutdown, you may trigger several rebalances that may cause short-lived topics assignments causing nothing except friction and potentially blocking the whole process.
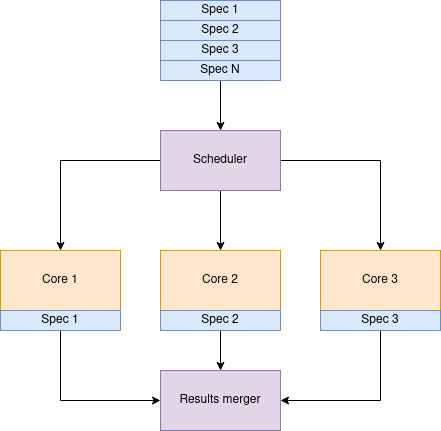
To mitigate this, Karafka shuts down actively and gracefully. That is, until the absolute end, it claims the ownership of given topics and partitions, actively waiting for all the current work to be finished. This looks more or less like so:
Note: Consumer groups internally in Karafka are a bit different than Kafka consumer groups. Here we focus on internal Karafka concepts.
Pinpointing the issue
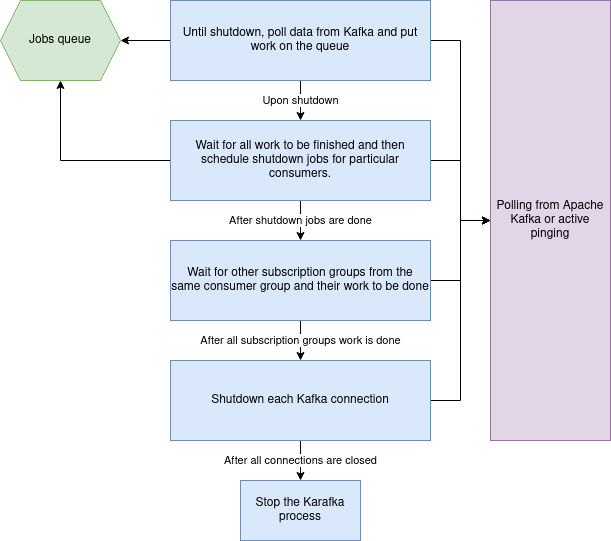
After several failed attempts and fixing other bugs, I added a lot of extra instrumentation to check what Karafka hangs on. It was hanging because there were hanging listener threads!
As stated above, to close Karafka gracefully, all work from the jobs queue needs to be finished, and listeners that poll data from Kafka need to be able to exit the polling loops. It's all coordinated using a job queue. The job queue we're using is pretty complex with some blocking capabilities, and you can read about it here, but the interesting part of the code can be reduced to this:
Those queues are used as semaphores in the polling loops until all the current work is done. Since each Queue is assigned to a different subscription group within its thread and hidden behind a concurrent map, there should be no problem. Right?
Reproduction
Once I had my crazy suspicion, I decided to reduce it down to a proof of concept:
require 'concurrent-ruby'
100.times do
ids = Set.new
semaphores = Concurrent::Hash.new { |h, k| h[k] = Queue.new }
100.times.map do
Thread.new do
ids << semaphores['test'].object_id
end
end.each(&:join)
raise "I expected 1 semaphore but got #{ids.size}" if ids.size != 1
end
once executed, boom:
poc.rb:13:in `<main>': I expected 1 semaphore but got 2 (RuntimeError)
There is more than one semaphore for one listener! This caused Karafka to wait until forced to stop because the worker thread would use a different semaphore than the listener thread.
But how is that even possible?
Well, Concurrent::Hash and Concurrent::Map initialization is indeed thread-safe but not precisely as you would expect them to be. The docs state that:
This version locks against the object itself for every method call, ensuring only one thread can be reading or writing at a time. This includes iteration methods like #each, which takes the lock repeatedly when reading an item.
"only one thread can be reading or writing at a time". However, we are doing both at different times. Our code:
semaphores = Concurrent::Hash.new do |h, k|
queue = Queue.new
h[k] = queue
end
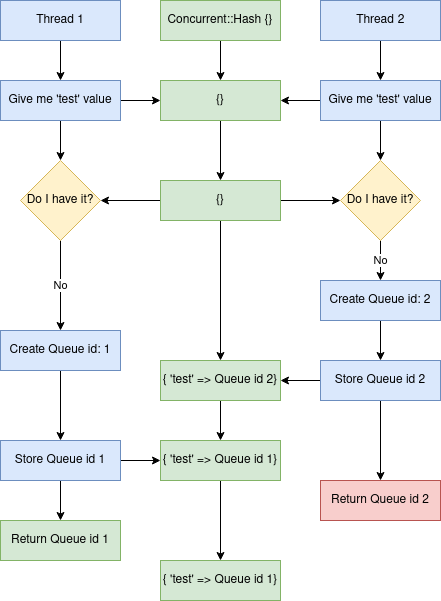
and the block content is not locked fully. One threads queue can overwrite the other if the Ruby scheduler stops the execution in the middle. Here's the flow of things happening in the form of a diagram:
Once in a while listener would receive a dangling queue object, effectively blocking the polling process.
Fixing the issue
This can be fixed either by replacing the Concurrent::Hash with Concurrent::Map and using the #compute_if_absent method or by introducing a lock inside of the Concurrent::Hash initialization block:
Concurrent::Map.new do |k, v|
k.compute_if_absent(v) { [] }
end
mutex = Mutex.new
Concurrent::Hash.new do |k, v|
mutex.synchronize do
break k[v] if k.key?(v)
k[v] = []
end
end
Okay, but what does Ruby on Rails and other projects do with all of this?
Fixing the world
I figured out that if I made this mistake, maybe others did. I decided to check my local gems to find occurrences quickly. Inside my local gem cache, I executed the following code:
and validated that I'm not an isolated case. I wasn't alone!
Then using Sourcegraph I pinpointed a few projects that had the potential for fixes:
rails (activesupport and actionview)
i18n
dry-schema
finite_machine
graphql-ruby
rom-factory
apache whimsy
krane
puppet
I am not a domain expert in any of those, and understanding the severity of each was beyond my time constraints, but I decided to give it a shot.
Rails (ActiveSupport and ActionView)
Within Rails, this "pattern" was used twice: in ActiveSupport and ActionView.
In ActionView, it was used within a cache:
PREFIXED_PARTIAL_NAMES = Concurrent::Map.new do |h, k|
h[k] = Concurrent::Map.new
end
and assuming that the cached result is stateless (same result each time for the same key), the issue could only cause an extra computation upon first parallel requests to this cache.
In the case of ActiveSupport, none of the concurrency code was needed, so I just replaced it with a simple Hash.
Both, luckily, were not that severe, though worth fixing nonetheless.
Both were merged, and this is how I became a Ruby on Rails contributor :)
i18n
This case was slightly more interesting because the concurrent cache stores all translations. In theory, this could cause similar leakage as in Karafka, effectively losing a language by loading it to a different Concurrent::Hash:
100.times.map do
Thread.new do
I18n.backend.store_translations(rand.to_s, :foo => { :bar => 'bar', :baz => 'baz' })
end
end.each(&:join)
I18n.available_locales.count #=> 1
This could lead to hard-to-debug problems. Once in a while, your system could raise something like this:
:en is not a valid locale (I18n::InvalidLocale)
without an apparent reason, and this problem would go away after a restart.
In my opinion, there are a few outcomes of this story:
Karafka has a solid test-suite!
If you are doing concurrency-related work, you better test it in a multi-threaded environment and test it well.
Concurrency is hard to many of us (maybe that's because we are special ;) ).
RTFM and read it well :)
Do not be afraid to help others by submitting pull requests!
On the other hand, looking at the frequency of this issue, it may be worth opening a discussion about changing this behavior and making the initialization fully locked.
Afterwords
Concurrent::Hash under cRuby is just a Hash. You can check it out here.