Karafka is a Ruby and Rails framework that simplifies the development of Apache Kafka-based applications. Among its varied features, the Filtering API provides enhanced control over the data flow.
The crux of this article is about managing offsets - unique identifiers for messages within Kafka's partitions. Often, there's a need to manage offsets alongside database operations within a transaction, especially when handling potential process crashes and anomalies, minimizing the risk of double processing.
For instance, if a SQL operation concludes successfully but the offset commit fails due to a crash, data could be processed again, leading to potential duplications or data integrity issues. Integrating offset management with database transactions using Karafka's Filtering API can help tackle this problem. It ensures the offset progress is tracked within the database transaction, maintaining data integrity even in crashes.
We'll explore this concept further in the coming sections, highlighting its practical implications and benefits.
The Importance of Offset Management in Kafka
In a world of streaming data, Kafka has cemented its role as an industry-standard platform for handling high-volume, real-time data feeds. At the heart of Kafka's functionality lies the concept of offsets, which are crucial in ensuring data consistency and reliability.
Offsets are unique identifiers assigned to each message within a Kafka partition. They serve as checkpoints that allow Kafka to track which messages have been consumed and which haven't. In other words, they are the mechanism by which Kafka maintains the state across distributed data streams, marking the position of every consumer in the stream. With them, it is possible to keep track of the data flowing through Kafka at any given time.
However, Kafka offset management has its challenges. Because it is entirely independent of database operations, there may be cases where a SQL operation finishes successfully, but the offset commit fails due to a process crash or an involuntary rebalance. This can lead to issues like data duplication, as when the system recovers, the data already processed by the SQL operation may be consumed again.
Below you can find an an example code and a graph that illustrates this problem:
def consume
Event.transaction do
messages.each do |message|
Event.insert(message.payload)
end
end
# Karafka does that automatically after batch is successfully processed
# however we do it here as well to better illustrate this scenario
mark_as_consumed(messages.last)
end

When using the #mark_as_consume, Karafka will store the offset locally and commit it periodically. This means there may be cases where the partition is lost, but the process still needs to be made aware of it. If that happens, while the database operation finishes, the offset won't be committed, and a different process may already be working with the same messages. This will result in inserting some of the events multiple times.
One way to partially mitigate would be to use mark_as_consumed! at the end of the transaction as follows:
def consume
Event.transaction do
messages.each do |message|
Event.insert(message.payload)
end
# Stop the transaction if we no longer own the partition
raise(ActiveRecord::Rollback) unless mark_as_consumed!(messages.last)
end
end
This, however, creates a new problem: what if the offset is committed, but the transaction fails?
Wouldn't it be amazing if we could store the offsets of processed messages or batches within the same DB transactions, ensuring that both always succeed or fail together?
Note 1: By default, Karafka will wait for the consumer to finish work and commit the offsets during rebalances unless the process is forcefully evicted from the consumer group.
Note 2: Yes this could be solved also by using unique keys for events, but this is not always the case. The example was reduced in complexity to focus on the transactional offset management and not a sophisticated SQL operations case.
Transactional Offset Management with the Filtering API
With Karafkas' Filtering API you can achieve exactly that!
By integrating offset management with the transactional integrity of the database using Karafka's Filtering API, we ensure that the offset progress is tracked within the database transaction itself. This approach helps maintain data integrity, even when crashes occur, by providing atomicity to the operation - meaning that all parts of the operation must succeed for the transaction to be committed. If any part fails, the entire transaction is rolled back, avoiding inconsistencies.
Karafka Filtering API is a powerful tool that allows developers to perform various actions around the consumption process. With the Filtering API, users can register multiple filters to validate, filter out messages as they arrive, and alter the polling process by pausing or starting from a different offset.
This time we will elevate the ability exposed by the Filtering API to inject an offset taken from the database in case it would not match the one stored in Kafka.
Defining the flow expectations
There are a few things we need to take into consideration to build a transactional offset management filter for Karafka:
- All SQL operations should have a timeout shorter than
max.poll.interval.ms to ensure we do not end up with an endless cycle of forced rebalances.
- Upon a conflict between the offset present in the database and Kafka, database offset should have the higher priority.
- Number of partitions is known (to simplify our code)
- Each topic partition has a pre-existing row in an appropriate table
- Our per-partition rows are always accessed with the
FOR UPDATE lock since they should be only used by the consumers that claim partition ownership. Those rows should not be used for anything else.
- Our per-partition row is used as a lock around the transaction happening during the consumption, ensuring that in case of reassignment, the other process is blocked on the initial offset selection until the transaction is finalized.
Keeping all of the above in mind, we can draw the expected flow of the initial offset selection:
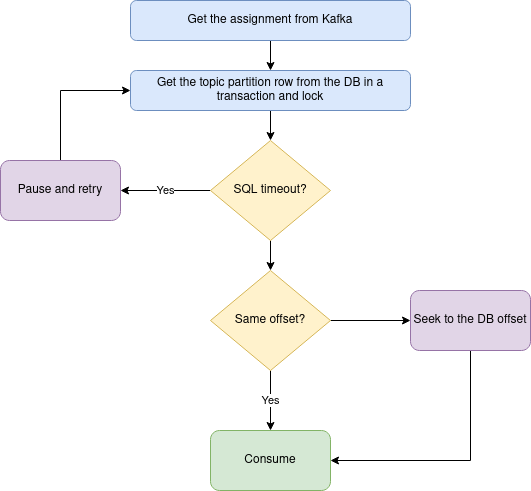
We still have to remember that consumption may happen with a delay and that the partition may be lost between the messages' delivery and their consumption. However, this is a separate issue we will tackle soon.
Because of the DB lock, we now know that:
- no one else owns the lock, which means there are no currently running operations on any other processes operating on the same topic partition (it does not mean there won't be any before the consumption in our process, but as mentioned, we will tackle this as well).
- we have the current Kafka offset and the DB one, and we can ensure that we start from the transactional one in case of a conflict.
What about the consumption itself? Can we just run it as previously? Well almost. We need a way to ensure that at the moment of locking the row, we own the partition. Yes, we may lose it during the processing, but as long as we hold the lock, any other process attempting to establish its starting offset will have to wait.
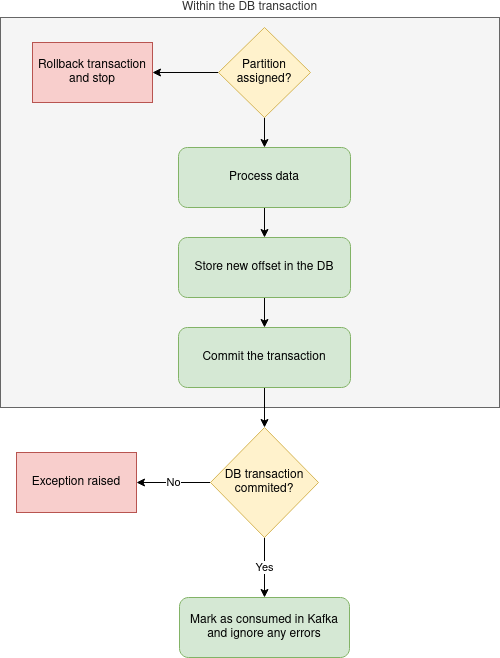
While the processing may end when we no longer own the partition, it was started with ownership confirmed. Hence, as long as we hold the lock, no other process can fetch the DB offset. This means that we can safely finish our DB operations and ignore potential Kafka offset commit failure.
Implementation
Partitions table
There's not much in our table design. We need to make sure we have a row per each topic partition and that we have a way to store the offset.
class CreatePartitions < ActiveRecord::Migration[6.1]
def change
create_table :kafka_partitions do |t|
t.string :topic_with_partition, unique: true, null: false
t.integer :offset, limit: 8, default: 0, null: fase
t.timestamps
end
end
end
Locking code
Code to ensure, that we can work with a given partition fully locked looks as followed:
class Partition < ApplicationRecord
self.table_name = :kafka_partitions
class << self
def locked(topic, partition, &block)
partition = find_by!(topic_with_partition: "#{topic}-#{partition}")
partition.with_lock('FOR UPDATE') do
yield(partition)
end
end
end
def mark_as_consumed(message)
update!(offset: message.offset + 1)
end
end
Filter for offset management
The most complex code resides in the filter. For the sake of simplicity, I left the lock timeout handling out:
class OffsetManager < Karafka::Pro::Processing::Filters::Base
def initialize(topic, partition)
@topic = topic
@partition = partition
@executed = false
@analyze = false
end
def apply!(messages)
# This filter should resolve sattes only on the first run because it's the first
# one after the partition assignment
# Every Karafka filter instance is reinitialized after a rebalance
if @executed
@analyze = false
return
end
# Care only on first run
@executed = true
@analyze = true
::Partition.locked(@topic, @partition) do |partition|
kafka_offset = messages.first.offset
# Selecting max will ensure that we always prioritize the DB one and since
# we always commit the transactional offset first, no risk in max
@start_offset = [partition.offset, kafka_offset].max
@mismatch = partition.offset != kafka_offset
end
# This will ensure that we do not pass any messages for consumption when seek will run
messages.clear if @mismatch
end
def applied?
true
end
def action
@analyze && @mismatch ? :seek : :skip
end
def cursor
::Karafka::Messages::Seek.new(
@topic,
@partition,
@start_offset
)
end
end
You can register this filter as follows:
topic :my_topic do
consumer Consumer
filter ->(topic, partition) { OffsetManager.new(topic, partition) }
end
Note that it is crucial to make sure this is the first filter that runs, as it needs to be aware of the initial offset received alongside the first message from Kafka.
Consumption alignment
The last remaining thing is the alignment of our consumption process. Similarly to our initial code, we do need to run in a transaction, however now it is being taken care of by our Partition#locked wrapper.
We use a synchronous #revoked? method that will return false in case our consumer lost the assignments it was working with.
def consume
successful = false
Partition.locked(
messages.metadata.topic,
messages.metadata.partition
) do |partition|
# Do not proceed if we have lost the assignment
raise(ActiveRecord::Rollback) if revoked?
# Do the work
messages.each do |message|
Event.insert(message.payload)
end
# Store the DB offset
partition.mark_as_consumed(messages.last)
successful = true
end
return unless successful
# Store Kafka offset
mark_as_consumed(messages.last)
end
Conclusion
My focus in this article was the careful and efficient management of Kafka's offsets, which are crucial for maintaining data integrity and consistency.
We explored how to integrate offset management with database transactions for handling scenarios involving process crashes. By doing so, the offset progress is meticulously tracked within the database transaction, significantly reducing the risk of data duplication or loss.
However, it's important to note that the examples and strategies discussed in this article have been simplified for clarity and understanding. In a real-world, production-grade environment, some extra development and adjustments may be required.