Introduction
I am thrilled to announce the release of Karafka 2.4, a significant milestone in the evolution of my Ruby and Rails multi-threaded efficient Kafka processing framework. This release builds upon the solid foundation laid by its predecessor, Karafka 2.3. It introduces many new features, enhancements, and improvements across the entire Karafka ecosystem, including Karafka, Web UI and WaterDrop.
In this article, I will discuss the most significant changes and enhancements introduced in Karafka 2.4. Please note that this is not an exhaustive list of all the changes but rather a curated selection of the most impactful and noteworthy improvements. For a complete list of changes, please refer to the detailed changelogs provided at the end of this article.
So, let's dive in and explore the exciting new features and enhancements that Karafka 2.4 offers!
Sponsorship and Community Support
The progress of Karafka 2.4 has been significantly driven by a collaborative effort, a blend of community contributions, and financial sponsorships. These supports, encompassing both code and investment, have been crucial for advancing both the OSS and Pro versions of Karafka.
Contributions from the community and sponsors not only enhance the capabilities of Karafka but also ensure its continued evolution, meeting the needs of a diverse user base. This collective backing is vital for sustaining the development and innovation of the whole ecosystem, helping maintain its position as a leading Kafka processing solution for Ruby and Ruby on Rails.
I want to extend my deepest gratitude to all our supporters. Your contributions, whether through code or funding, drive this project forward. Thank you for your continued trust and commitment to making Karafka a success. It would not be what it is without you!
Karafka Enhancements
Karafka 2.4 introduces many improvements and new features to the core framework aimed at enhancing performance, flexibility, and ease of use. Let's take a closer look at some of the most significant enhancements.
Declarative Topics Alignment
Karafka 2.4 introduces several new commands that enhance the management and alignment of Kafka topics within your application.
The karafka topics alter command allows for declarative topics alignment. This feature ensures that your existing Kafka topics are always in sync with your application's configuration, eliminating the need for manual intervention and reducing the risk of configuration drift.
With the karafka topics migrate command, you can now perform declarative topics configuration alignment in addition to creating missing topics and repartitioning existing ones. This streamlined approach simplifies the management of your Kafka topics. It ensures that your application is always working with the correct topic configurations.
Additionally, the new karafka topics plan command provides a planning mechanism for topic migrations. It displays the changes that will be applied when the migration is executed, offering a preview to help you understand the impact of the migration before it is carried out. This helps in ensuring that all intended modifications align with your Kafka configuration and application requirements.
bundle exec karafka topics plan
Following topics will have configuration changes:
~ default:
~ retention.ms: "86400000" => "186400000"
~ visits:
~ cleanup.policy: "delete" => "compact"
~ retention.ms: "604800000" => "3600000"
~ segment.ms: "604800000" => "86400000"
~ segment.bytes: "1073741824" => "104857600"Direct Assignments
Karafka 2.4 introduces direct assignments. This powerful feature lets you precisely control which partitions and topics each consumer should process. This capability is handy for building complex data pipelines and applications that require explicit partition handling.
You can bypass the standard consumer group partition assignment mechanism with direct assignments and manually specify partition ownership. This level of control enables you to optimize data locality, tailor processing logic to specific partitions, and ensure that your application can handle the nuances of your data and processing requirements.
A practical use case for direct assignments is the exciting prospect of merging streams from independent topics and partitions. For instance, you can configure consumers to process specific partitions across multiple topics, facilitating the efficient merging of these streams for complex processing tasks such as event sequencing or time-series analysis. This provides precise control over data flows and dependencies, enhancing the flexibility and robustness of your Kafka-based systems.
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
topic 'users_events' do
consumer UsersEventsConsumer
# Directly assign partitions 0 and 1
assign(0, 1)
end
topic 'shops_events' do
consumer ShopsEventsConsumer
# Assign 3 partitions matching the expected users events
assing(0, 1, 2)
end
end
endConsumer Piping API
This feature allows you to easily pipe messages from one topic to another. It facilitates the creation of complex data processing workflows and enables seamless integration between different application components.
The consumer piping API provides a set of methods, such as #pipe_async, #pipe_sync, #pipe_many_async, and #pipe_many_sync, that allow you to pipe messages easily. You can also customize the piped messages by defining an #enhance_pipe_message method in your consumer, enabling you to add or modify headers, change the payload, or apply any other transformations before forwarding messages.
class PaymentConsumer < ApplicationConsumer
def consume
payment_process(messages.payloads)
# After processing, pipe messages to the next service
pipe_many_async(
topic: 'stock_check',
messages: messages
)
end
endEnhanced Deserialization
Karafka 2.4 significantly improves the deserialization process, making it more flexible and powerful. The framework now supports custom deserializers for message keys and headers in addition to the payload deserializer. This allows you to handle various data formats and structures across different aspects of your Kafka messages.
class KarafkaApp < Karafka::App
setup do |config|
# ...
end
routes.draw do
topic :financial_transactions do
consumer TransactionsConsumer
deserializers(
payload: AvroDeserializer.new,
key: IntegerDeserializer.new,
headers: JsonDeserializer.new
)
end
topic :system_logs do
consumer LogsConsumer
deserializers(
payload: TextDeserializer.new
# Uses the default framework deserializers
# for headers and key
)
end
end
endAdmin Configs API
I introduced the Karafka::Admin::Configs API, which provides tools for managing configuration settings for Kafka brokers and topics. This API supports retrieving configuration details (describe) and incremental alterations (alter) to these configurations, giving you fine-grained control over your Kafka environment.
With the Admin Configs API, you can easily retrieve and modify configuration settings for topics and brokers. This enables you to optimize performance, ensure security, and maintain reliability in your Kafka setup. The API provides a Ruby-friendly interface for managing these configurations, making integrating with your existing codebase easier.
# Describe topic configurations
resource = Karafka::Admin::Configs::Resource.new(type: :topic, name: 'example')
topics = Karafka::Admin::Configs.describe(resource)
topics.each do |topic|
topic.configs.each do |config|
puts "#{topic.name} #{config.name}: #{config.value}"
end
end
# Alter topic configurations
resource = Karafka::Admin::Configs::Resource.new(type: :topic, name: 'example')
# Set retention to 2 hours
resource.set('retention.ms', '7200000')
# Apply the changes
Karafka::Admin::Configs.alter(resource)Fine-Grained Control Over DLQ Handling
This version introduces more refined control over handling messages when they fail to process. It includes settings to specify whether DLQ operations should be synchronous or asynchronous. This flexibility allows users to optimize performance and reliability according to their application's specific needs.
class KarafkaApp < Karafka::App
routes.draw do
topic :orders_states do
consumer OrdersStatesConsumer
dead_letter_queue(
topic: 'dead_messages',
max_retries: 2,
dispatch_method: :produce_sync,
marking_method: :mark_as_consumed!
)
end
end
endSupport for Custom OAuth Providers
Support for custom OAuth providers has been on my list for a long time. It allows you to seamlessly integrate with any OAuth-based authentication system.
With the new custom OAuth provider support, you can easily configure Karafka and WaterDrop to work with your preferred OAuth provider, ensuring secure and authenticated communication with your Kafka cluster.
This feature would not be possible without extensive contributions and support from Bruce Szalwinski and HotelEngine.
class KarafkaApp < Karafka::App
setup do |config|
# Other config options...
config.kafka = {
'bootstrap.servers': 'your-kafka-server:9098',
'security.protocol': 'sasl_ssl',
'sasl.mechanisms': 'OAUTHBEARER'
}
config.oauth.token_provider_listener = OAuthTokenRefresher.new
end
endSupport enable.partition.eof Fast Yielding
Thanks to enhancements in the polling engine, the enable.partition.eof configuration option enhances responsiveness in message consumption scenarios. By default, when reaching the end of a partition, consumers typically wait for more messages based on the max_wait_time or max_messages settings. This can introduce delays, especially in real-time data processing environments.
Setting kafka enable.partition.eof to truemodifies this behavior. Instead of waiting at the end of a partition, Karafka immediately yields control, allowing any accumulated messages to be processed immediately. This feature reduces latency by eliminating unnecessary wait times, thus optimizing throughput and responsiveness in high-throughput environments where quick data handling is crucial.
Web UI Enhancements
Not only has Karafka been upgraded, but the Web UI has also received a host of enhancements. In the sections below, I'll delve into the significant updates and new features introduced to improve usability, management capabilities, and diagnostic tools, providing a more robust and intuitive experience.
Consumers Lifecycle Control
With the release of Karafka 2.4's new 0.9.0 Web UI, I've introduced enhanced management capabilities similar to those found in Sidekiq, allowing administrators to quiet and stop both all or particular consumer processes as needed. This addition significantly expands your control over your consumer lifecycle directly from the Web UI, making it easier to manage consumer activity during various operational scenarios.
The quiet functionality is a boon when preparing for system maintenance or upgrades. It lowers consumers activity level without completely stopping them, ensuring ongoing processes complete their work while new jobs are paused. On the other hand, the stop functionality is ideal for completely halting consumer processes, which is beneficial during critical updates or when decommissioning services.
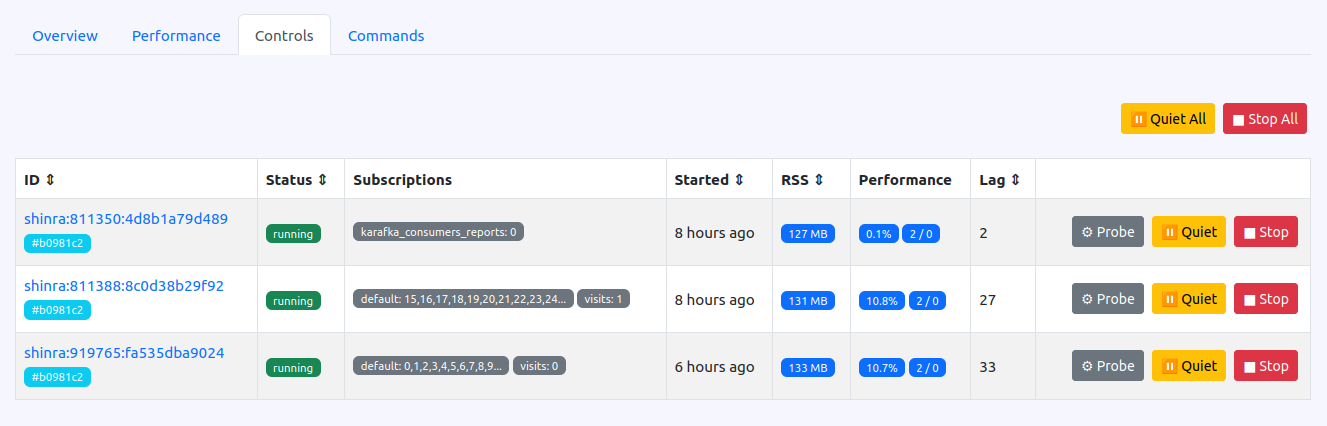
These new controls enhance operational flexibility and improve the ability to maintain system stability and performance by managing the load on your Kafka consumers more effectively. This level of direct control is a substantial step forward in managing complex Kafka environments within Karafka's Web UI.
Please note, that during each consumer process startup, this feature initiates a special "invisible" connection to Kafka. This connection is used exclusively for administrative commands. To disable this feature, you can set the config.commanding.active configuration option to false.
Consumers Probing
I also introduced the probing feature in addition to consumer lifecycle management. This powerful tool enhances the ability to manage and diagnose consumer processes in real-time. Probing allows the request of detailed runtime information from active consumers, providing deep insights into their internal state without disrupting their operations or leaving the Web UI.
This is precious for diagnosing issues within stuck consumer processes as it enables to capture backtraces and other critical runtime details. By utilizing probing, you can pinpoint performance bottlenecks, identify deadlocks, and gather valuable data that can aid in troubleshooting and optimizing consumer operations.
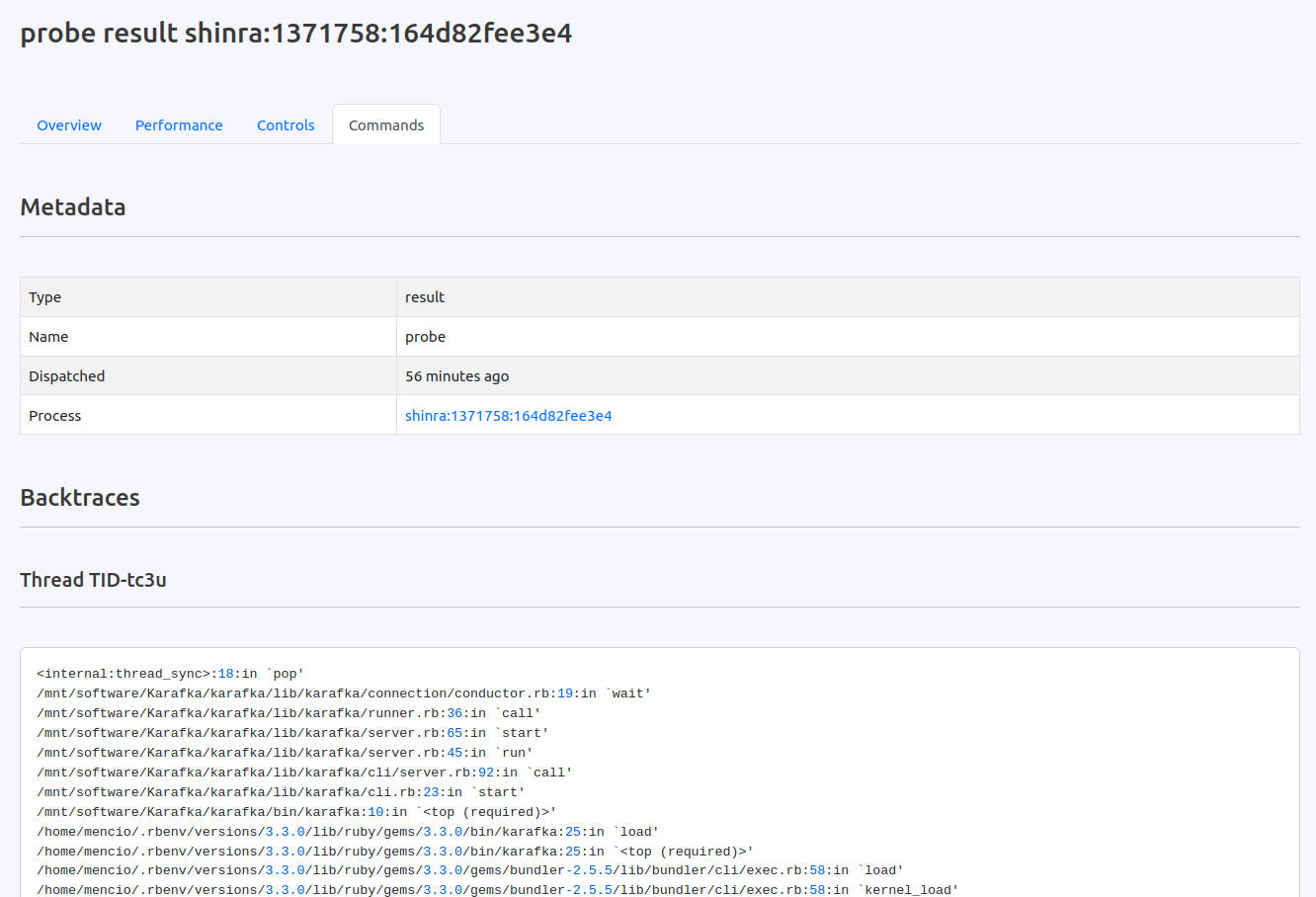
Probing is designed to be non-intrusive, ensuring that while you gain visibility into the consumer's activity, the process continues to handle messages, thus maintaining system throughput and stability.
Cluster Perspective Health
The "Cluster Lags" feature in the Karafka Web UI provides a crucial perspective on the health and performance of your Kafka cluster by directly measuring the lag across different topics and partitions using Kafka as the source of truth. This functionality is essential for comprehensive monitoring and management, offering a clear view of Kafka's metrics on message processing delays.
By focusing on Kafka's internal lag metrics, you can obtain an independent and accurate assessment of message processing delays, which is essential for diagnosing cluster issues.
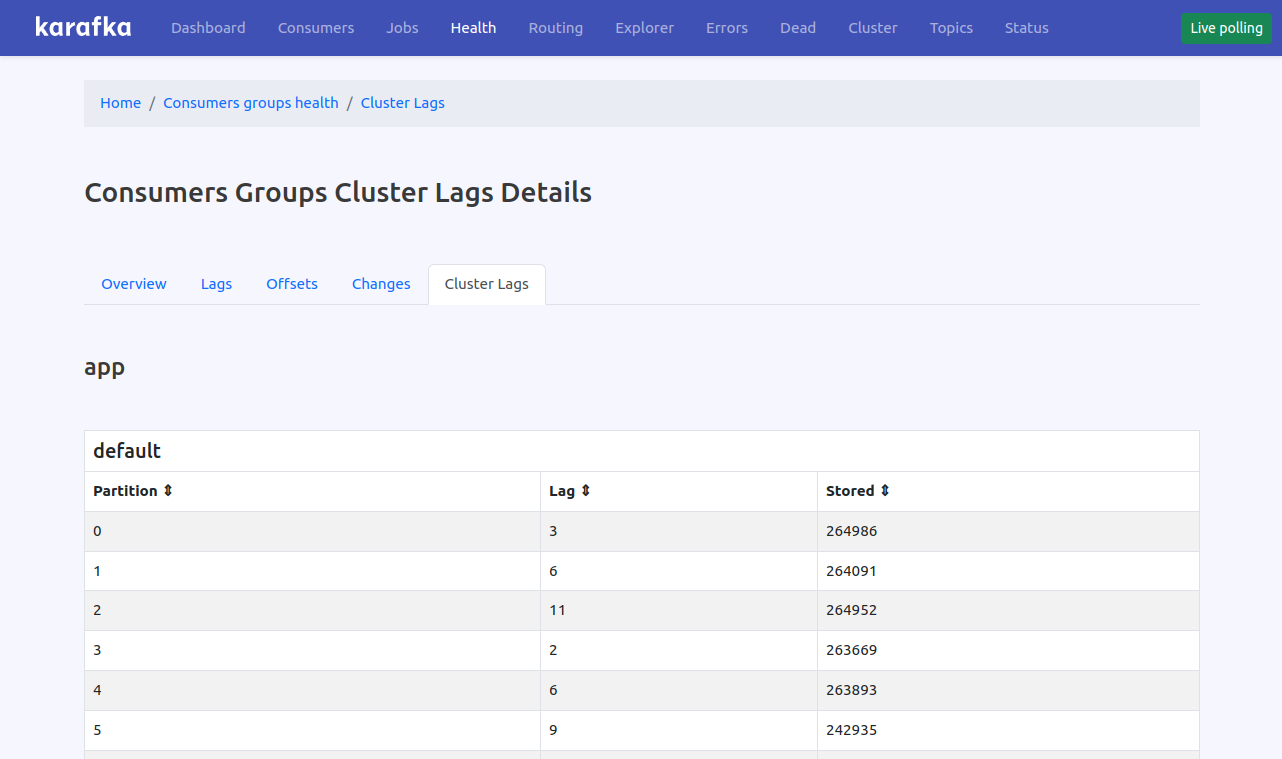
The Cluster Lags functionality pulls data directly from Kafka, ensuring that the insights provided are timely and unaffected by any anomalies or issues within individual consumer processes. This feature is convenient in environments where:
- Consumer processes are temporarily down or inactive, which might obscure real-time performance metrics.
- Consumers are misbehaving or not processing messages at the expected rate, potentially leading to increased lag and data processing bottlenecks.
Topics and Brokers Configs Insights
Alongside the Admin Config API in Karafka, the "Configuration Insights" under the Topics Insights tab has been introduced, providing a thorough view of each Kafka topic's settings.
The Configuration Explorer presents a detailed breakdown of each configuration attribute for a topic:
- Name: Displays the name of the Kafka configuration parameter.
- Value: Shows the current setting of the parameter.
- Default: Indicates whether the setting is a cluster default or has been modified.
- Sensitive: Marks if the parameter contains sensitive information, such as passwords.
- Read only: Identifies whether the parameter can be modified or is fixed.
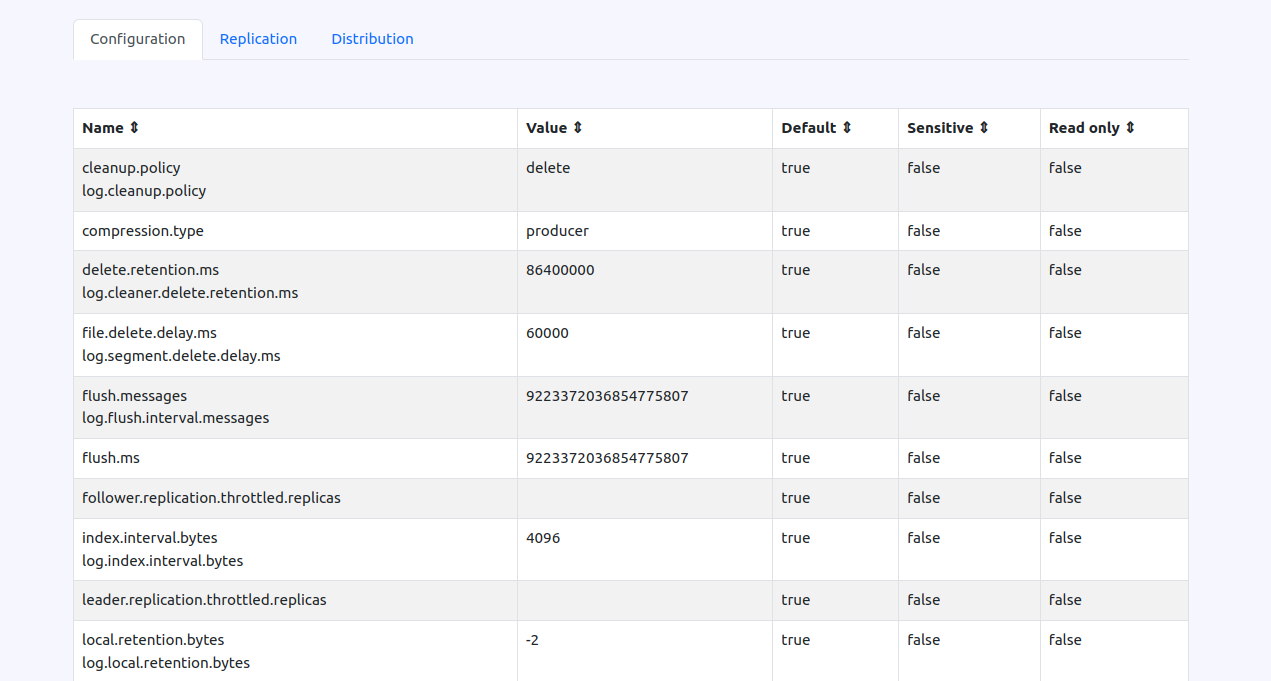
This detailed view allows users to quickly understand and verify the configuration of each topic.
Similar capabilities to explore each broker configuration have also been added.
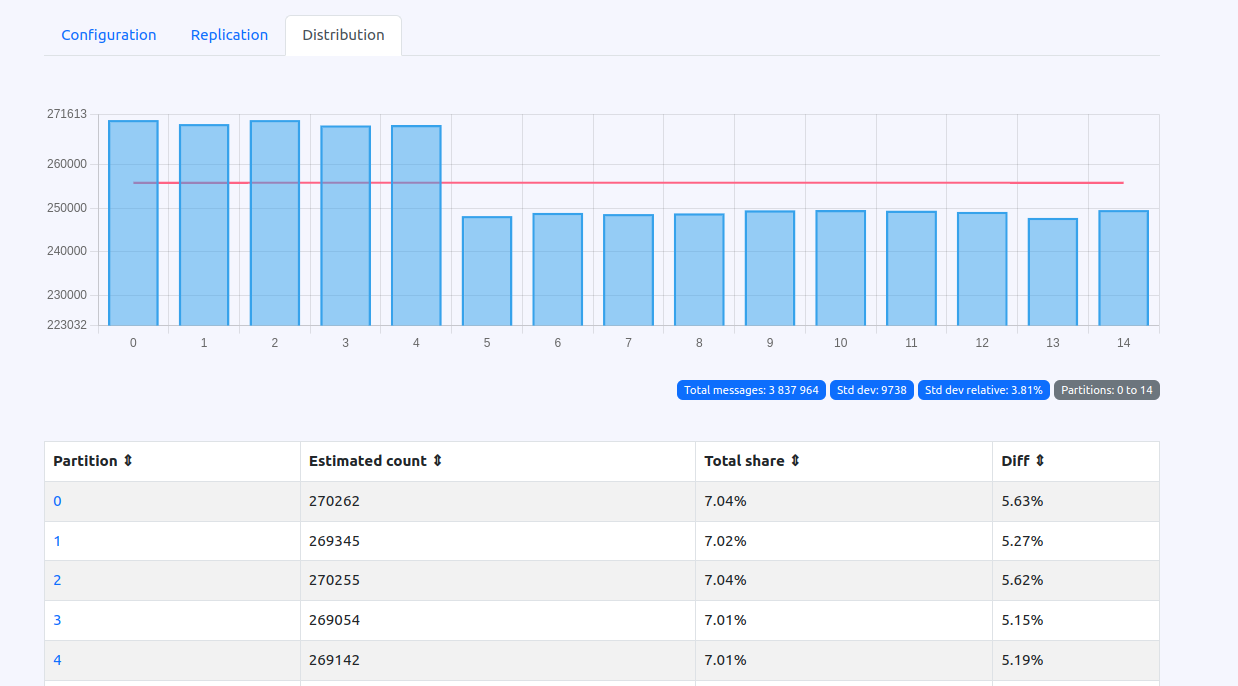
Partitions Messages Distribution Insights
Another new view offers details of message distribution across topic partitions, which is crucial for identifying imbalances that could impact Kafka performance. The Web UI's Distribution tab provides both visual and analytical insights to detect "hot" (overly active) or "cold" (less active) partitions with these key metrics:
- Partition: Identifies specific partitions.
- Estimated count: Estimates messages within the partition.
- Total share: Shows this partition's percentage of total messages.
- Diff: Highlights message count disparities, aiding in rebalance efforts.
The tab also includes a graph visually representing the message load across partitions, aiding quick identification of distribution issues and facilitating more effective partition management.
DLQ Topics Auto-Classification
Starting with this release, the Web UI will automatically classify topics as Dead Letter Queue (DLQ). Regardless of case sensitivity, any topic name containing dlq or dead_letter will be identified as a DLQ topic. This feature supports naming conventions like DLQ, dlq, Dead_Letter, or DEAD_LETTER, ensuring that all relevant topics are efficiently managed under the DLQ view.
General UI Improvements
Alongside new features, I also improved the user experience across its Web UI. Key improvements include:
- Displaying the first offset in the OSS jobs tab for better job tracking.
- Limiting the length of keys in the explorer's list view for cleaner, more readable displays.
- Enhancing responsiveness on larger screens by increasing maximum width settings.
- Making tables responsive to ensure usability across different device sizes.
- Adding page titles to all Web UI pages to facilitate easier navigation and accessibility.
These upgrades collectively enhance the interface's functionality and aesthetics, ensuring a more efficient and user-friendly environment for managing Karafka operations.
WaterDrop Enhancements
Enhanced Timeouts and Delivery Guarantees
Karafka 2.4 uses a new WaterDrop version that introduces several improvements to timeout and delivery guarantee mechanisms, ensuring a more reliable and predictable message production experience. This change prevents scenarios where the delivery report verdict is not final, providing a more deterministic and reliable message delivery process.
Sync Operations Performance Improvements
Through the contributions of Tomasz Pajor, WaterDrop has significantly enhanced the performance of sync operations. Previously, sync operations relied on a sleep-based mechanism, which has now been replaced with a non-blocking condition variable approach. This change is especially beneficial for sync operations with low acks levels (1 or 2) on fast clusters. The new method can increase the speed of these operations by up to 40% while also reducing overall CPU usage by as much as 10%. This optimization not only boosts performance but also enhances the efficiency and responsiveness of the system.
Support for Custom OAuth Providers
Like Karafka, WaterDrop now supports custom OAuth providers, enhancing its capabilities for secure communication with Kafka clusters.
Upgrade Notes and Compatibility
Karafka 2.4 and its related components introduce a few breaking changes necessary to advance the ecosystem. While changes that disrupt existing implementations are kept to a minimum, they are sometimes essential for progress. The migration path for these changes is thoroughly documented to ensure a smooth transition. Detailed information and guidance can be found at Karafka Upgrades 2.4.
Migrating to Karafka 2.4 should be manageable. I have made every effort to ensure that any breaking changes are justified and well-documented, minimizing potential disruptions. Additionally, should any critical errors arise, efforts will be made to backport fixes to Karafka 2.3 when feasible. This approach ensures that while we push the boundaries of what Karafka can do, your existing systems remain stable and reliable.
Summary
Karafka 2.4 is a significant milestone in the evolution of the Karafka framework. It brings a host of powerful new features, enhancements, and improvements to the Ruby and Rails Kafka processing ecosystem.
Whether you are a seasoned Karafka user or just getting started with Kafka processing in Ruby and Rails, Karafka 2.4 provides a robust, flexible, and intuitive framework that empowers you to easily build sophisticated and scalable Kafka-based applications.
I thank the Karafka community for their invaluable feedback, contributions, and support. Your input has been instrumental in shaping this release and driving the continued evolution of the framework.
